Kafka topic
Overview
Apache Kafkais an end-to-end event streaming platform that:
- Publishes (writes) and subscribes to (reads) streams of events from sources like databases, cloud services, and software applications.
- Stores these events durably and reliably for as long as you want.
- Processes and reacts to the event streams in real-time and retrospectively.
Those events are organized and stored in topics. These topics are then partitioned over buckets located on different Kafka brokers.
Event streaming thus ensures a continuous flow and interpretation of data so that the right information is at the right place, at the right time for your key use cases.
The Kafka Topic destination supports batch and real-time syncs.
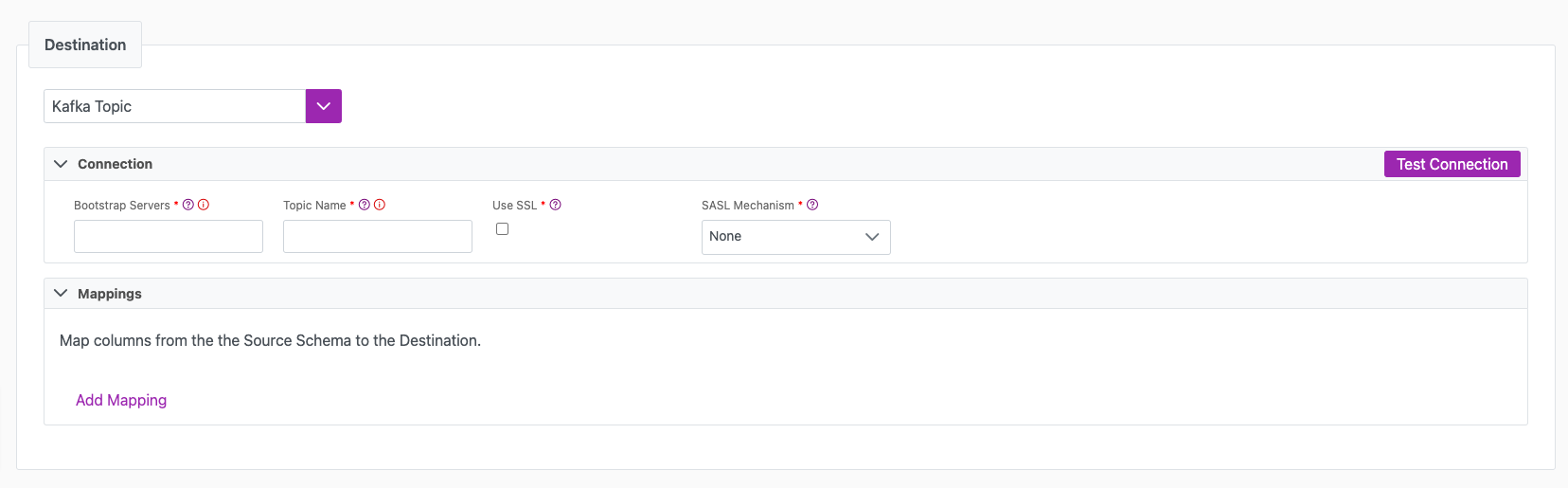
Destination tab
The following table outlines the mandatory and optional parameters you will find on the Destination tab.
- Destination details
- Column Mapping
- Schema Registry
The following parameters will help to define your data sync destination and how it functions.
| Parameter | Description | Example |
|---|---|---|
| Destination | Mandatory. Select your destination from the drop down menu. | Kafka Topic |
| Bootstrap Servers | Mandatory. Bootstrap Servers are a list of host/port pairs to use for establishing the initial connection to the Kafka cluster. This parameter should a CSV list of "broker host" or "host:port" | localhost:9092,another.host:9092 |
| Topic Name | Mandatory. The name of the Kafka Topic that messages will be produced to. | |
| Use SSL | Check this if you want to connect to Kafka over SSL | |
| SASL Mechanism | Mandatory. Select the SASL (Simple Authentication and Security Layer) Mechanism to use for authentication: - None - PLAIN - SCRAM-SHA-256 - SCRAM-SHA-512 - OATHBEARER (default) - OATHBEARER (OIDC) | |
| Test Connection | You can use the "Test Connection" button to ensure that your credentials are properly configured to access your destination. If configured correctly, a "Connection Successful" pop-up will appear. If configured incorrectly, a "Connection Failed" pop-up will appear along with a link to the applicable error logs to help you troubleshoot. |
The Column Mappingsection is where you define which source columns you want to sync to which destination columns. You can repeat the values for multiple columns.
The names you specify in your "Target Column" value will turn into attributes in a JSON payload that will be constructed and pushed to Kafka. The name of this target column can be whatever you choose, but we recommend maintaining your naming convention across columns for simplicity.
| Parameter | Description | Example |
|---|---|---|
| Source Column | Mandatory. The name of your column as it appears in the source. | Name |
| Target Column | Mandatory. The name of your column as it appears in the destination. | Name |
Kafka Schema Registry is supported in Cinchy v5.13.1+.
It provides a centralized repository for managing and validating schemas for topic message data, and for serialization and deserialization of the data over the network.
Considerations
-
Review the documentation here for steps on how to configure topics to work with Schema Registry.
-
Schema Registry is not supported in syncs that use a Dynamic Topic. For real-time syncs, messages will be logged to the Execution Errors table. For batch syncs, the job will fail with a
404: Schema not foundexception. -
This functionality supports JSON schema. It does not support other types such as Avro, Protobuf, or Thrift.
-
If schema validation is configured in your Destination but is not configured in Kafka, the job will fail with an Error
404: Schema not foundexception. -
Schema auto-registration is disabled. If a corresponding schema for a given payload is not found in schema registry, it won't be automatically registered and will subsequently throw an error.
Mapping
The following table shows how Cinchy data types are mapped to JSON schema data types in Kafka.
| Cinchy type | JSON schema type |
|---|---|
| Number | Number |
| Text | String |
| Bool | Boolean |
| Date | String (with 'format' field) |
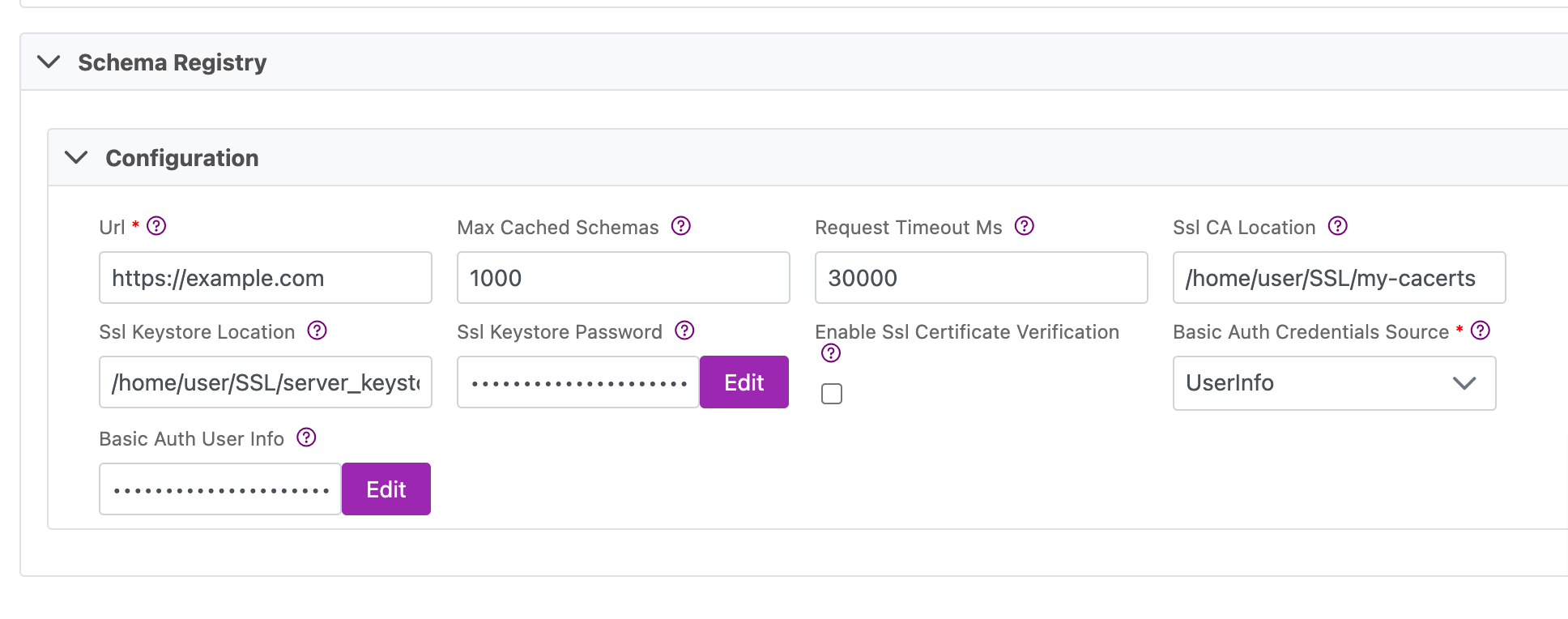
Connections Parameters
| Parameter | Description | Example |
|---|---|---|
| Url | Mandatory. The URL of the Schema Registry server. | <https://example.com> |
| Max Cached Schemas | Specifies the maximum number of schemas the client should cache locally (for efficiency). If left blank, the default is 1000 | 1000 |
| Request Timeout Ms | Specifies the timeout for requests to Schema Registry. default: 30000 | 30000 |
| Ssl CA Location | File or directory path to CA certificate(s) for verifying the schema registry's key. | /home/user/SSL/my-cacerts |
| Ssl Keystore Location | Path to client's keystore (PKCS#12) used for authentication. | /home/user/SSL/server_keystore |
| Ssl Keystore Password | Client's keystore (PKCS#12) password. This value is encrypted by the platform. | /home/user/SSL/server_keystore_password |
| Enable Ssl Certificate Verification | Enable/Disable SSL server certificate verification. Only use in contained test/dev environments. | Disabled by default. |
| Basic Auth User Info | Specifies the Kafka configuration property schema.registry.basic.auth.credentials.source which provides basic authentication. - UserInfo: Credentials are specified via the schema.registry.basic.auth.user.info config property in the form username:password. If schema.registry.basic.auth.user.info is not set, authentication is disabled. - SaslInherit: Credentials are specified via the sasl.username and sasl.password configuration properties. | |
| Basic Auth Credentials Source | Mandatory when using UserInfo authentication. Basic Auth credentials specified in the form of username:password. This value is encrypted by the platform. | admin:p@$$w0rd |
| SASL Username | Username for SASL Authentication. | admin |
| SASL Password | Password for the above username. This value is encrypted by the platform. | p@$$w0rd |
Next steps
- Define yourSync Actions.
- Add in your Post Sync Scripts, if required.
- Define your Permissions.
- If you are running a real-time sync, set up your Listener Config and enable it to begin your sync.
- If you are running a batch sync, click Jobs > Start a Job to begin your sync.
Appendix A
Configuring a Dynamic Topic
Cinchy v5.10 added the ability to use a '@COLUMN' custom formula to enable a dynamic parameterized Kafka Topic when syncing into a Kafka destination.
To use this functionality, follow the below instructions.
- Define which table and column you want to use for your dynamic topic. In this example, the table is
[Product].[Tasks]and the column is "Quarter". - Create a data sync using a Cinchy Table source and a Kafka Topic destination.
- Ensure that the column defined in step 1 is loaded into your Schema.
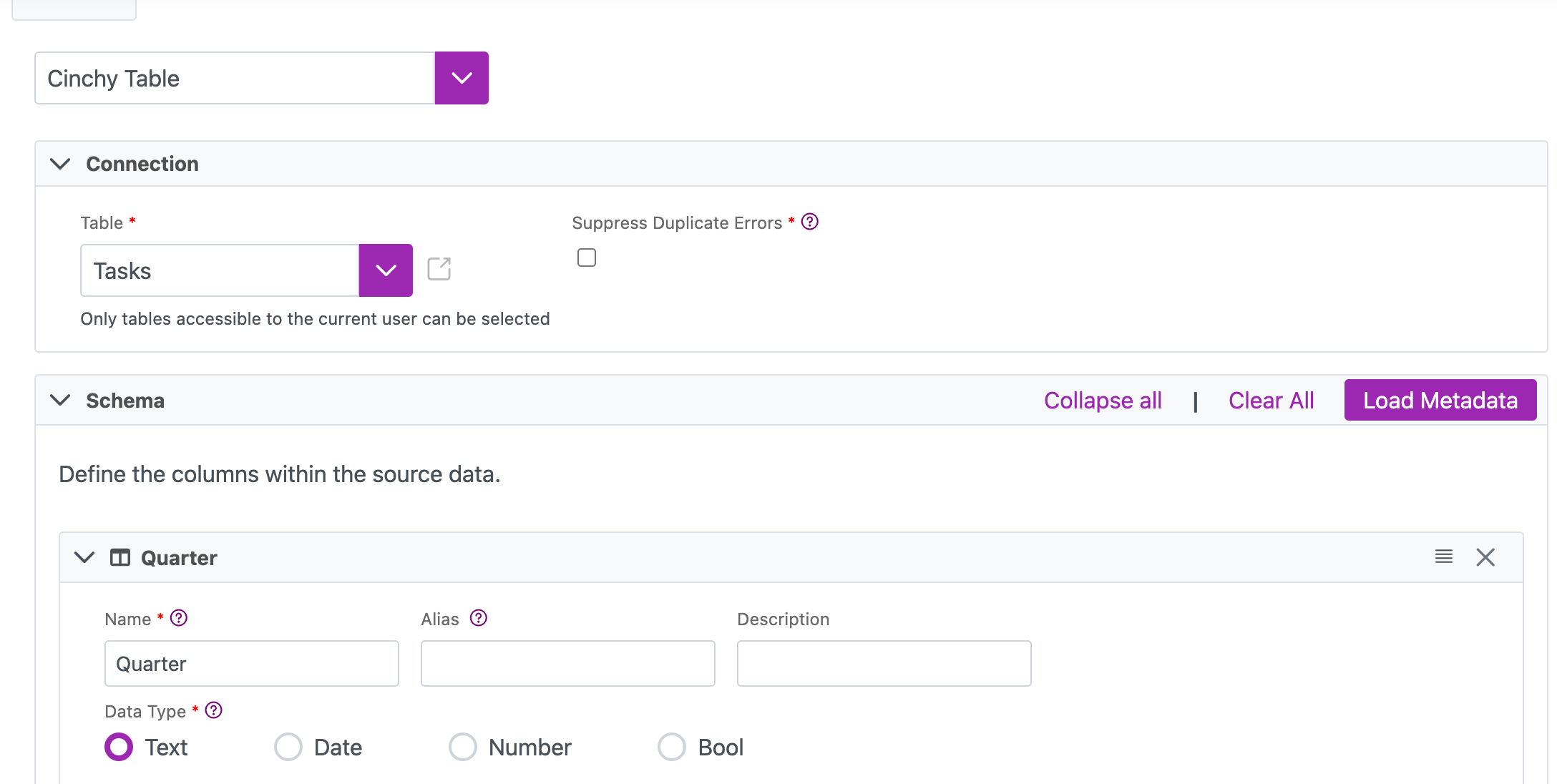
- Ensure that the column defined in step 1 is loaded into your Schema.
- In the 'Topic' field of the Kafka destination, insert "@COLUMN('<column-name>')". In this example, the formula would be @COLUMN('Quarter').
