Kafka Topic
Overview
Apache Kafka is an end-to-end event streaming platform that:
- Publishes (writes) and subscribes to (reads) streams of events from sources like databases, cloud services, and software applications.
- Stores these events durably and reliably for as long as you want.
- Processes and reacts to the event streams in real-time and retrospectively.
Those events are organized and durably stored in topics. These topics are then partitioned over a number of buckets located on different Kafka brokers.
Event streaming thus ensures a continuous flow and interpretation of data so that the right information is at the right place, at the right time for your key use cases.
Example use case
You currently use Kafka to store the metrics for user logins, but being stuck in the Kafka silo means that you can't easily use this data across a range of business use cases or teams. You can use a batch sync to liberate your data into Cinchy.
The Kafka Topic source supports real-time syncs.
\
Info tab
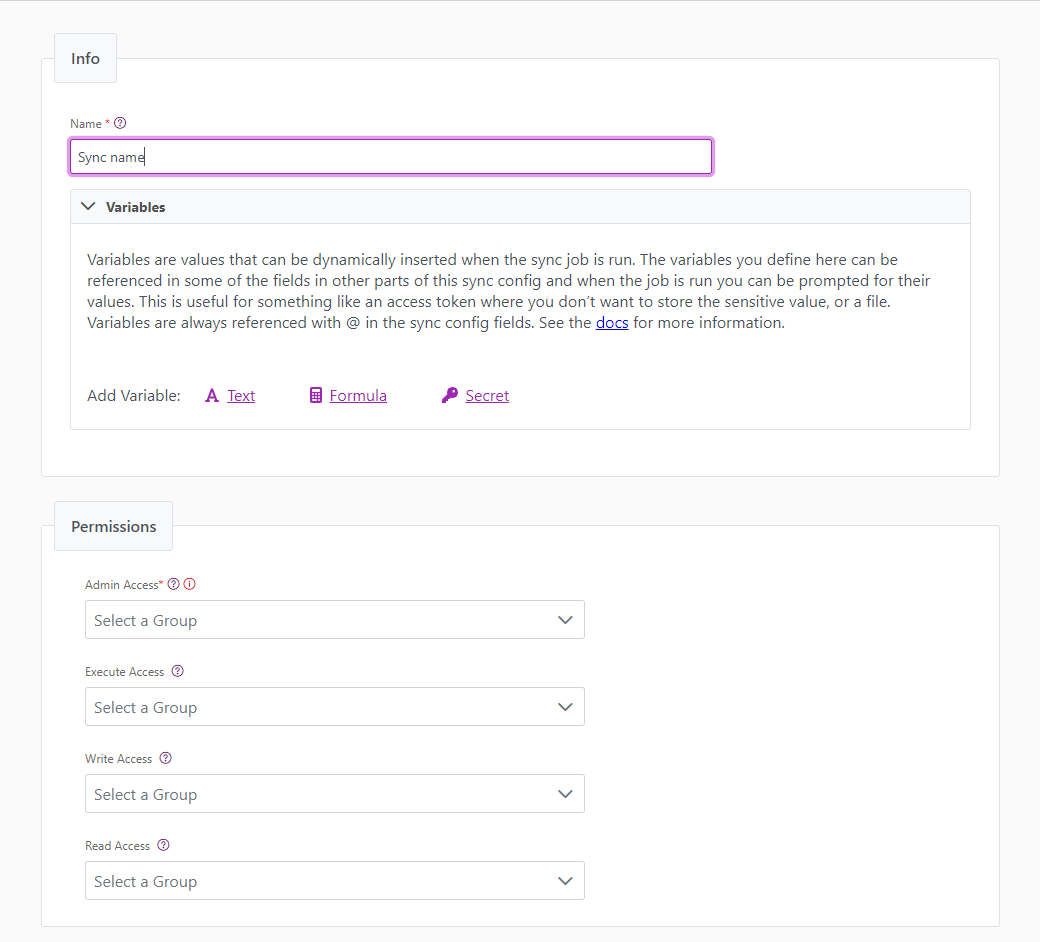
You can find the parameters in the Info tab below (Image 1).
Values
| Parameter | Description | Example |
|---|---|---|
| Title | Mandatory. Input a name for your data sync | Kafka topic to Cinchy |
| Description | Optional. Add in a description for your sync. There is a 500 character limit in thie field. | |
| Variables | Optional. Review our documentation on Variables here for more information about this field. | |
| Permissions | Data syncs are role based access systems where you can give specific groups read, write, execute, and/or all of the above with admin access. Inputting at least an Admin Group is mandatory. |
Source tab
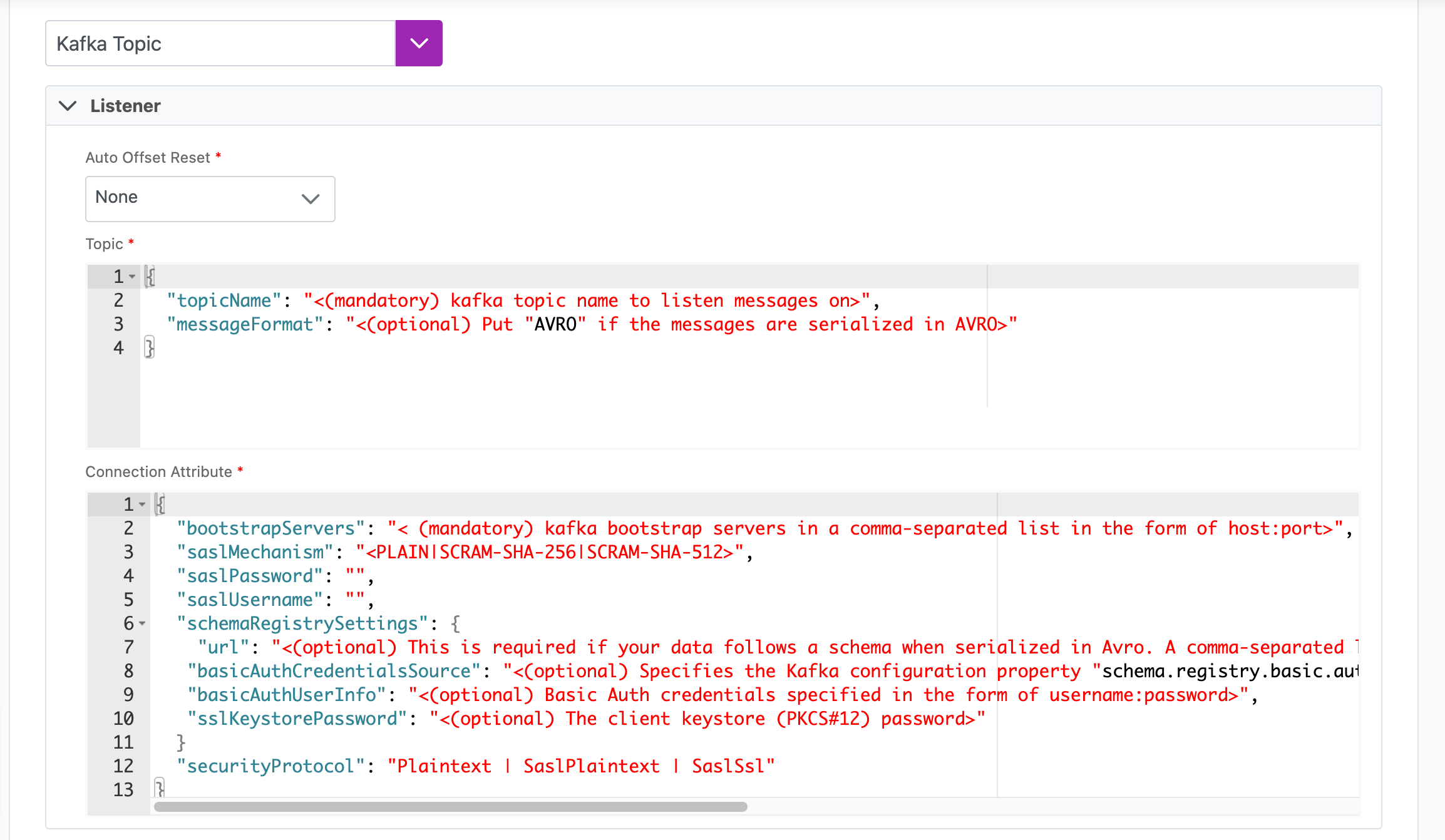
The following table outlines the mandatory and optional parameters you will find on the Source tab (Image 2).
- Source Details
- Listener Configuration
- Schema
- Filter
The following parameters will help to define your data sync source and how it functions.
| Parameter | Description | Example |
|---|---|---|
| Source | Mandatory. Select your source from the drop-down menu. | Kafka Topic |
To set up a real-time sync, you must configure your Listener values. You can do so through the Connections UI.
Note that If there is more than one listener associated with your data sync, you will need to configure the addition listeners via the Listener Configuration table.
Reset behaviour
| Parameter | Description | Example |
|---|---|---|
| Auto Offset Reset | Earliest, Latest, or None. In situations where there's no last message ID or it's invalid, this setting decides where to start reading events. Earliest starts from the queue beginning, useful for reprocessing all events. Latest picks up after the last processed value. None won't start reading events. You can switch between these types after initial setup. More details. | None |
Topic JSON
The below table can be used to help create your Topic JSON needed to set up a real-time sync.
| Parameter | Description | Example |
|---|---|---|
| topicName | Mandatory. This is the Kafka topic name to listen messages on. | |
| messageFormat | Optional. Put "AVRO" if your messages are serialized in AVRO, otherwise leave blank. |
Example Topic JSON
{
"topicName": "<(mandatory) kafka topic name to listen messages on>",
"messageFormat": "<(optional) Put "AVRO" if the messages are serialized in AVRO>"
}
Connection attributes
The below table can be used to help create your Connection Attributes JSON needed to set up a real-time sync.
| Parameter | Description |
|---|---|
bootstrapServers | List the Kafka bootstrap servers in a comma-separated list. This should be in the form of host:port |
saslMechanism | This will be either PLAIN, SCRAM-SHA-256, or SCRAM-SHA-512. SCRAM-SHA-256 must be formatted as: SCRAMSHA256 SCRAM-SHA-512 must be formatted as: SCRAMSHA512 |
saslPassword | The password for your chosen SASL mechanism |
saslUsername | The username for your chosen SASL mechanism. |
url | This is required if your data follows a schema when serialized in AVRO. It's a comma-separated list of URLs for schema registry instances that are used to register or lookup schemas. |
| basicAuthCredentialsSource | Specifies the Kafka configuration property "schema.registry.basic.auth.credentials.source" that provides the basic authentication credentials. This can be "UserInfo" | "SaslInherit" |
| basicAuthUserInfo | Basic Auth credentials specified in the form of username:password |
| sslKeystorePassword | This is the client keystore (PKCS#12) password. |
securityProtocol | Kafka supports cluster encryption and authentication, which can encrypt data-in-transit between your applications and Kafka.Use this field to specify which protocol will be used for communication between client and server. Cinchy currently supports the following options: Plaintext, SaslPlaintext, or SaslSsl. Paintext: Unauthenticated, non-encrypted. SaslPlaintext: SASL-based authentication, non-encrypted. SaslSSL: SASL-based authentication, TLS-based encryption. If no parameter is specified, this will default to Plaintext. |
{
"bootstrapServers": "< (mandatory) kafka bootstrap servers in a comma-separated list in the form of host:port>",
"saslMechanism": "<PLAIN|SCRAM-SHA-256|SCRAM-SHA-512>",
"saslPassword": "",
"saslUsername": "",
"schemaRegistrySettings": {
"url": "<(optional) This is required if your data follows a schema when serialized in Avro. A comma-separated list of URLs for schema registry instances that are used to register or lookup schemas. >",
"basicAuthCredentialsSource": "<(optional) Specifies the Kafka configuration property "schema.registry.basic.auth.credentials.source" that provides the basic authentication credentials, this can be "UserInfo" | "SaslInherit">",
"basicAuthUserInfo": "<(optional) Basic Auth credentials specified in the form of username:password>",
"sslKeystorePassword": "<(optional) The client keystore (PKCS#12) password>"
}
"securityProtocol": "Plaintext | SaslPlaintext | SaslSsl"
}
**The** Schema section is where you define which source columns you want to sync in your connection. You can repeat the values for multiple columns.
| Parameter | Description | Example |
|---|---|---|
| Name | Mandatory. The name of your column as it appears in the source. | Name |
| Alias | Optional. You may choose to use an alias on your column so that it has a different name in the data sync. | |
| Data Type | Mandatory. The data type of the column values. | Text |
| Description | Optional. You may choose to add a description to your column. |
Select Show Advanced for more options for the Schema section.
| Parameter | Description | Example |
|---|---|---|
| Mandatory |
| |
| Validate Data |
| |
| Trim Whitespace | Optional if data type = text. For Text data types, you can choose whether to trim the whitespace._ | |
| Max Length | Optional if data type = text. You can input a numerical value in this field that represents the maximum length of the data that can be synced in your column. If the value is exceeded, the row will be rejected (you can find this error in the Execution Log). |
You can choose to add in a Transformation > String Replacement by inputting the following:
| Parameter | Description | Example |
|---|---|---|
| Pattern | Mandatory if using a Transformation. The pattern for your string replacement. | |
| Replacement | What you want to replace your pattern with. |
You have the option to add a source filter to your data sync. Please review the documentation here for more information on source filters.
Next steps
- Configure your Destination
- Define your Sync Actions.
- Add in your Post Sync Scripts, if required.
- If more than one listener is needed for a real-time sync, configure it/them via the Listener Config table.
- To run a real-time sync, enable your Listener from the Execution tab.